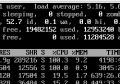
Linux新学
基础命令
find与ls
ls
1 .只显示目录
ls -F | grep "/$"
-F 文件类型(File type)。在每一个列举项目之后添加一个符号。这些符号包括: / 表明是一个目录; @ 表明是到其它文件的符号链接; * 表明是一个可执行文件
ls -al | grep "^d"
2.只显示文件
ls -al | grep "^-"
-R 递归(recursive)。该选项递归地列举所有目录(在当前目录之下)的内容。
-S 按大小排序
-s 在每个文件前面加上文件大小输出
-t 按时间排序
3.find与ls的结合
find的结果无法显示日期或者说文件详情,此时用ls结合显示
find . -type f -mtime +5| xargs ls -l --time-style='+%Y-%m-%d
或
find . -type f -mtime +5 -exec ls -l --time-style='+%Y-%m-%d' {} \;注意结尾是“{} \;”
df的用法
只列总量,以易懂方式
df -hs /etc
注意与“df -hS”的区别,后者只统计不包括/etc的子目录容量
磁盘分区与挂载
1.查看磁盘状况
lsblk -f
看“磁盘列表”,也能看到现有分区及分区类型和UUID
blkid
查看各磁盘分区的UUID
2.查看磁盘分区表类型(很重要)
parted /dev/sda print
目的是查看分区表是GPT的还是MBR
3.用 gdisk或者fdisk 分区
注意分区表是GPT用gdisk,分区表是MBR就用fdisk就行了。
4.更新Linux核心分区表信息
partprobe -s
查看
lsblk /dev/sda
cat /proc/partitions
5.格式化分区
格式化为ext4分区
mkfs.ext4 /dev/sda5
格式化为xfx分区
mkfs.xfs /dev/sda5
其中后者可针对RAID进行效能优化,详见http://linux.vbird.org/linux_basic/0230filesystem.php#mkfs.xfs 和 http://linux.vbird.org/linux_basic/0230filesystem.php#mkfs.xfs.raid
6.挂载
mount -t |xfs|ext3|ext4|reiserfs|vfat|iso9660|nfs|cifs|smbfs -o async|sync,atime|noatime,ro|rw,auto|noauto,dev|nodev,suid|nosuid,exec|noexec,user|nouser | -o default,remout | -o codepage=950,iocharset=utf8
装置文件名 挂载点
上面命令中,“|”表示分隔各选项,斜体 表示各参数
开机挂载的话,需用root权限修改/etc/fstab文件(修改完,用mount -a验证修改是否正确)
如果/etc/fstab修改错误开机无法正常启动,那么需进入单人维护模式,执行
mount -n -o remount,rw /
来重新挂载/目录
回环设备
回环设备( ‘loopback device’)允许用户以一个普通磁盘文件虚拟一个块设备。设想一个磁盘设备,对它的所有读写操作都将被重定向到读写一个名为 disk-image 的普通文件而非操作实际磁盘或分区的轨道和扇区。(当然,disk-image 必须存在于一个实际的磁盘上,而这个磁盘必须比虚拟的磁盘容量更大。)回环设备允许你这样使用一个普通文件。
回环设备以/dev/loop0、/dev/loop1 等命名。每个设备可虚拟一个块设备。注意只有超级用户才有权限设置回环设备。
回环设备的使用与其它任何块设备相同。特别是,你可以在这个设备上创建文件系统并像普通的磁盘一样将它挂载在系统中。这样的一个将全部内容保存在一个普通文件中的文件系统,被称为虚拟文件系统(virtual file system)(译者注:这个用法并不常见。VFS 通常另有所指,如指代 Linux 内核中有关文件系统抽象的代码层次等)。
在类 UNIX 系统里,loop 设备是一种伪设备(pseudo-device),或者也可以说是仿真设备。它能使我们像块设备一样访问一个文件。
在使用之前,一个 loop 设备必须要和一个文件进行连接。这种结合方式给用户提供了一个替代块特殊文件的接口。因此,如果这个文件包含有一个完整的文件系统,那么这个文件就可以像一个磁盘设备一样被 mount 起来。
那么mount -o loop就不难理解了——当有大的文件(比如系统镜像的ISO文件、虚拟机创建的vmdk文件或者dd生成的大的文件)需要挂载,就用loop。
压缩与解压缩
tar 跟的参数中,“z”、“j”、“J”分别表示生成“gz”、“bz2”、“xz”文件,压缩比依次升高。
参数“c”、“t”、“x”依次表示“创建压缩”、“查看压缩”、“解压缩”的意思。“v”表示“展示详情”,“f”一般放最后,后面要跟具体的文件。
常见组合“zxvf”、“jxvf”、“czvf”。
解开单一文件——1、先
tar tvf 文件名 |grep 关键词找出待解压文件的具体名称,然后tar xvf 打包档 待解开挡名。步骤里,根据不同的“gz”、“bz2”、“xz”文件,加入不同的“z”、“j”、“J”参数就好了。
VI
vim 选择文本,删除,复制,粘贴
文本的选择,对于编辑器来说,是很基本的东西,也经常被用到,总结如下:
v 从光标当前位置开始,光标所经过的地方会被选中,再按一下v结束。
V 从光标当前行开始,光标经过的行都会被选中,再按一下V结束。
ctrl + v从光标当前位置开始,选中光标起点和终点所构成的矩形区域,再按一下ctrl + v结束。ggVG 选中全部的文本, 其中gg为跳到行首,V选中整行,G末尾
选中后就可以用编辑命令对其进行编辑,如
d 删除
y 复制 (默认是复制到”寄存器)
p 粘贴 (默认从”寄存器取出内容粘贴)
+y 复制到系统剪贴板(也就是vim的+寄存器)
+p 从系统剪贴板粘贴
vim命令总结
1、 删除字符
要删除一个字符,只需要将光标移到该字符上按下x。
2、 删除一行
删除一整行内容使用dd命令。删除后下面的行会移上来填补空缺。
3、 删除换行符
在Vim中你可以把两行合并为一行,也就是说两行之间的换行符被删除了:命令是J。
4.、撤销
如果你误删了过多的内容。显然你可以再输入一遍,但是命令u 更简便,它可以撤消上一次的操作。
5、重做
如果你撤消了多次,你还可以用ctr+r(重做)来反转撤消的动作。换句话说,它是对撤消的撤消。撤消命令还有另一种形式,U命令,它一次撤消对一行的全部操作。第二次使用该命令则会撤消前一个U的操作。用u和ctr+r你可以找回任何一个操作状态。
6、追加
i命令可以在当前光标之前插入文本。a命令可以在当前光标之后插入文本。o命令可以在当前行的下面另起一行,并使当前模式转为Insert模式。O命令(注意是大写的字母O)将在当前行的上面另起一行。
7、使用命令计数
假设你要向上移动9行。这可以用kkkkkkkkk或9k来完成。事实上,很多命令都可以接受一个数字作为重复执行同一命令的次数。比如刚才的例子,要在行尾追加三个感叹号,当时用的命令是a!!!。另一个办法是用3a!命令。3说明该命令将被重复执行3次。同样,删除3个字符可以用3x。指定的数字要紧挨在它所要修饰的命令前面。
8、退出
要退出Vim,用命令ZZ。该命令保存当前文件并退出Vim。
9、 放弃编辑
丢弃所有的修改并退出,用命令:q!。用:e!命令放弃所有修改并重新载入该文件的原始内容。
10、以Word为单位的移动
使用w命令可以将光标向前移动一个word的首字符上;比如3w将光标向前移动3个words。b命令则将光标向后移动到前一个word的首字符上。e命令会将光标移动到下一个word的最后一个字符。命令ge,它将光标移动到前一个word的最后一个字符上。
11、移动到行首或行尾
$命令将光标移动到当前行行尾。如果你的键盘上有一个键,它的作用也一样。^命令将光标移动到当前行的第一个非空白字符上。0命令则总是把光标移动到当前行的第一个字符上。$命令还可接受一个计数,如1$会将光标移动到当前行行尾,2$则会移动到下一行的行尾,如此类推。0命令却不能接受类似这样的计数,命令^前加上一个计数也没有任何效果。
12、移动到指定字符上
命令fx在当前行上查找下一个字符’x’(向右方向),可以带一个命令计数F命令向左方向搜索。tx命令形同fx命令,只不过它不是把光标停留在被搜索字符上,而是在它之前的一个字符上。提示:t意为’To’。该命令的反方向版是Tx。这4个命令都可以用;来重复。以,也是重复同样的命令,但是方向与原命令的方向相反。 注意:这段文字中的’x’代表任意被搜索的字符。
13、以匹配一个括号为目的移动
用命令%跳转到与当前光标下的括号相匹配的那一个括号上去。如果当前光标在”(“上,它就向前跳转到与它匹配的”)”上,如果当前在”)”上,它就向后自动跳转到匹配的”(“上去.
14、移动到指定行
用G命令指定一个命令计数,这个命令就会把光标定位到由命令计数指定的行上。比如33G就会把光标置于第33行上。没有指定命令计数作为参数的话, G会把光标定位到最后一行上。gg命令是跳转到第一行的快捷的方法。
另一个移动到某行的方法是在命令%。之前指定一个命令计数比如50%将会把光标定位在文件的中间.90%跳到接近文件尾的地方。
命令H,M,L,分别将光标跳转到第一行,中间行,结尾行部分。
15、告诉你当前的位置
使用CTRL-G命令,可在窗口下方显示当前光标所在行,在全文本的多少行,以及占文本行数的百分比,比如如果正好在文本中间,那么显示为‘50%’:set number在每行的前面显示一个行号。相反关闭行号用命令:set nonumber。:set ruler在Vim窗口的右下角显示当前光标位置。
16、滚屏
ctrl+u显示文本的窗口向上滚动了半屏。crtl+d命令将窗口向下移动半屏。一次滚动一行可以使用ctrl+e(向上滚动)和ctrl+y(向下滚动)。要向前滚动一整屏使用命令crtl+f。另外crtl+b是它的反向版。zz命令会把当前行置为屏幕正央,zt命令会把当前行置于屏幕顶端,zb则把当前行置于屏幕底端.
ctrl+f和crtl+b最常用。
17、简单搜索
/string使用n命令。如果你知道你要找的确切位置是目标字符串的第几次出现,还可以在n之前放置一个命令计数。3n会去查找目标字符串的第3次出现。 ?命令与/的工作相同,只是搜索方向相反.N命令会重复前一次查找,但是与最初用/或?指定的搜索方向相反。
如果查找内容忽略大小写,则用命令:set ignorecase, 返回精确匹配用命令:set noignorecase。
18、在文本中查找下一个word
把光标定位于这个word上然后按下\*键。Vim将会取当前光标所在的word并将它作用目标字符串进行搜索。\#命令是\*的反向版。还可以在这两个命令前加一个命令计数:3\*查找当前光标下的word的第三次出现。
19、查找整个word
如果你用/the来查找Vim也会匹配到’there’这样的单词。要查找作为独立单词的‘the’,使用如下命令:/the\\>。\\>是一个特殊的记法,它只匹配一个word的结束处。近似地,\\<匹配到一个word的开始处。这样查找作为一个word的”the”就可以用:/\\。
20、高亮显示搜索结果
开启这一功能用:set hlsearch,关闭这一功能::set nohlsearch。如果只是想去掉当前的高亮显示,可以使用下面的命令::nohlsearch(可以简写为:noh)。
21、 匹配一行的开头与结尾
^字符匹配一行的开头。$字符匹配一行的末尾。 所以/was$只匹配位于一行末尾的单词was,所以/^was只匹配位于一行开始的单词was。
22、 匹配任何的单字符
.这个字符可以匹配到任何字符。比如c.m可以匹配任何前一个字符是’c’,后一个字符是’m’的情况,不管中间的字符是什么。
23、匹配特殊字符
放一个反斜杠在特殊字符前面。如果你查找’ter。’,用命令/ter\\。
24、使用标记
当你用G命令从一个地方跳转到另一个地方时,Vim会记得你起跳的位置。这个位置在Vim中是一个标记。使用命令``可以使你跳回到刚才的出发点。
``命令可以在两点之间来回跳转。ctrl+o命令是跳转到你更早些时间停置光标的位置(提示:O意为older). ctrl+i则是跳回到后来停置光标的更新的位置(提示:I在键盘上位于O前面)。
注:使用ctrl+i与按下键一样。
25、具名标记
命令ma将当前光标下的位置名之为标记a。从a到z一共可以使用26个自定义的标记。要跳转到一个你定义过的标记,使用命令`marks,marks就是定义的标记的名字。命令`a使你跳转到a所在行的行首,`a会精确定位a所在的位置。命令::marks用来查看标记的列表。
命令delm!删除所有标记。
26.、操作符命令和位移
dw命令可以删除一个word,d4w命令是删除4个word,依此类推。类似有d2e、d$。此类命令有一个固定的模式:操作符命令+位移命令。首先键入一个操作符命令。比如d是一个删除操作符。接下来是一个位移命。比如w。这样任何移动光标命令所及之处,都是命令的作用范围。
27、改变文本
操作符命令是c,改变命令。它的行为与d命令类似,不过在命令执行后会进入INSERT模式。比如cw改变一个word。或者,更准确地说,它删除一个word并让你置身于INSERT模式。
cc命令可以改变整行。不过仍保持原来的缩进。
c$改变当前光标到行尾的内容。
快捷命令:x 代表dl(删除当前光标下的字符) X 代表dh(删除当前光标左边的字符) D 代表d$(删除到行尾的内容) C 代表c$(修改到行尾的内容) s 代表cl(修改一个字符) S 代表cc(修改一整行)
命令3dw和d3w都是删除3个word。第一个命令3dw可以看作是删除一个word的操作执行3次;第二个命令d3w是一次删除3个word。这是其中不明显的差异。事实上你可以在两处都放上命令记数,比如,3d2w是删除两个word,重复执行3次,总共是6个word。
28、替换单个字符
r命令不是一个操作符命令。它等待你键入下一个字符用以替换当前光标下的那个字符。r命令前辍以一个命令记数是将多个字符都替换为即将输入的那个字符。要把一个字符替换为一个换行符使用r。它会删除一个字符并插入一个换行符。在此处使用命令记数只会删除指定个数的字符:4r将把4个字符替换为一个换行符。
29、重复改动
.命令会重复上一次做出的改动。.命令会重复你做出的所有修改,除了u命令ctrl+r和以冒号开头的命令。.需要在Normal模式下执行,它重复的是命令,而不是被改动的内容
30、Visual模式
按v可以进入Visual模式。移动光标以覆盖你想操纵的文本范围。同时被选中的文本会以高亮显示。最后键入操作符命令。
31、移动文本
以d或x这样的命令删除文本时,被删除的内容还是被保存了起来。你还可以用p命令把它取回来。P命令是把被去回的内容放在光标之前,p则是放在光标之后。对于以dd删除的整行内容,P会把它置于当前行的上一行。p则是至于当前行的后一行。也可以对命令p和P命令使用命令记数。它的效果是同样的内容被取回指定的次数。这样一来dd之后的3p就可以把被删除行的3 份副本放到当前位置。
命令xp将光标所在的字符与后一个字符交换。
32、复制文本(VIM编辑器内复制)
y操作符命令会把文本复制到一个寄存器3中。然后可以用p命令把它取回。因为”y”是一个操作符命令,所以你可以用yw来复制一个word. 同样可以使用命令记数。如下例中用y2w命令复制两个word,yy命令复制一整行,Y也是复制整行的内容,复制当前光标至行尾的命令是y$。
33、 文本对象
diw 删除当前光标所在的word(不包括空白字符)daw 删除当前光标所在的word(包括空白字符)
Bash部分
1、type
type用于查看指令是属于file(外部指令)还是alias还是builtin。
2、指令下达与编辑
指令过长,可用“\”来跳脱连接内容。
指令输入完未执行前,可用下列组合键来删除或者辅助编辑:
| 组合键 | 功能与示范 |
|---|---|
| ctrl+u或者ctrl+k | 从光标处向前删除字符串ctrl+u,从光标处向后删除字符串ctrl+k |
| ctrl+a或者ctrl+e | 将光标移动到指令串最前面/最后面 |
3、变量
可用echo来显示变量值
注意变量的设定规则:
= 用来设定变量值,=两边不能有空格
变量不能以数字开头
注意变量赋值时“ ”与‘ ‘的区别
赋值时可用“\”来跳脱特殊字符
赋值时可引用指令结果,格式`指令`
变量内容累加时的格式,变量名=“$变量名”累加内容 或者变量名=“${变量名}”累加内容
export用来指定环境变量
unset用来取消变量
4、环境变量
ENV用来查看有哪些环境变量,重要的有
PATH、HISTSIZE、LANG等SET查看bash内所有变量,重要的有
PS1(命令提示符、注意其修改方法)、$(Shell本身的PID)以及?(上个命令回传值)
5、read、array与declare
read
read -p 提示内容 -t 等待秒数 变量名declare
-a 将变量定义为数组(array)类型
-i 将变量定义为整数(integer)类型
-x 将变量定义为环境变量
-r 将变量定义为只读(readonly)变量
6、变量内容的删除、取代和替换
总的格式:${变量名+替换符号+删、取、替内容},其中“替换符号”有:
#——表示从前往后删除最短数据
##——表示从前往后删除最长数据
/——表示替换字符串内容,格式“/旧字符串/新字符串”
7、路径与指令的搜寻顺序
“绝对路径”–>”alias指令”–>bash内建(builtin)–>$PATH顺序搜寻
8、bash组合键
ctrl+c —— 表示结束当前命令
ctrl+d —— 表示结束当前输入
ctrl+m —— 等同于“Enter”键
ctrl+s —— 表示暂停屏幕输出
ctrl+q —— 表示恢复屏幕输出
ctrl+u —— 提示符下,删除整列命令
ctrl+z —— 暂停当前命令的执行
9、通配符与特殊符号
通配符
| 符号 | 意义 |
|---|---|
| * | 代表任意无穷多字符 |
| ? | 代表单一一个字符 |
| [] | 代表一定有一个在方括号内的字符,如[abcd] |
| [-] | 代表在方括号编码顺序内的字符,如[0-9]、[a-z]等 |
| [^] | 表示反向选择,如[^abc]表示有一个字符,只要是非a,b,c就接受 |
特殊符号
| 符号 | 意义 |
|---|---|
| # | 在script中,表示批注 |
| \ | 跳脱符号,将特殊字符或者通配符变成一般字符 |
| | | 管线符,分隔两个管线命令的界限 |
| ; | 分隔符,连续下达命令的分隔符号 |
| ~ | 用户家目录 |
| $ | 取用变数前导符,变量前需加的变量取代值 |
| & | 工作控制,将指令变成背景下工作 |
| ! | 逻辑运算意义上的“非” |
| / | 目录符号:路径的分隔符号 |
| >,>> | 数据流重导向:输出重导向,分别是“取代”和“累加” |
| <,<< | 数据流重导向,输入重导向 |
| ‘ ‘ | 单引号,不具有变量置换功能 |
| “ “ | 双引号,具有变量置换功能 |
| `` | 两个``之间可执行指令,亦可用$()的方式 |
| () | 为子shell的起始与结束 |
| {} | 在中间为命令块的组合 |
10、数据流重导向
数据流重导向中,1、标准输入stdin,代码0,用<或者<<;2、标准输出stdout,代码1,用>或者>>;3、标准错误输出stderr,代码2,用2>或者2>>。 2>&1表示将标准错误输出也记录到输出文件中。
11、命令判断依据
;表示命令连续下达。 &&表示前者执行成功,则后者执行,否则后者不执行。
|| 则表示的相反,前者执行不成功则执行后者。
12、管线命令
关于管线命令,整理成表吧
| 命令 | 命令参数与用法 |
|---|---|
| cut | cut -d’分隔字符’ -f fields cut -c 字符区间 -d :后面接分隔字符。与 -f 一起使用; -f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思; -c :以字符 (characters) 的单位取出固定字符区间; 例如:echo ${PATH} | cut -d ‘:’ -f 3,5 |
| grep | grep [-acinv] [–color=auto] ‘搜寻字符串’ filename -a :将 binary 文件以 text 文件的方式搜寻数据 -c :计算找到 ‘搜寻字符串’ 的次数 -i :忽略大小写的不同,所以大小写视为相同 -n :顺便输出行号 -v :反向选择,亦即显示出没有 ‘搜寻字符串’ 内容的那一行! |
| sort | sort [-fbMnrtuk] [file or stdin] -f :忽略大小写的差异,例如 A 与 a 视为编码相同; -b :忽略最前面的空格符部分; -M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法; -n :使用『纯数字』进行排序(默认是以文字型态来排序的); -r :反向排序; -u :就是 uniq ,相同的数据中,仅出现一行代表; -t :分隔符,预设是用 [tab] 键来分隔; -k :以那个区间 (field) 来进行排序的意思 实例:cat /etc/passwd | sort -t ‘:’ -k 3 |
| uniq | uniq [-ic] -i :忽略大小写字符的不同; -c :进行计数 例如:last | cut -d ‘ ‘ -f1 | sort | uniq -c |
| wc | wc [-lwm] -l :仅列出行; -w :仅列出多少字(英文单字); -m :多少字符; 例如:last | grep [a-zA-Z] | grep -v ‘wtmp’ | grep -v ‘reboot’ | grep -v ‘unknown’ |wc -l |
| tee | 双重导向tee [-a] file -a :以累加 (append) 的方式,将数据加入 file 当中! last | tee last.list | cut -d ” ” -f1 |
| tr | tr [-ds] SET1 … -d :删除讯息当中的 SET1 这个字符串; -s :取代掉重复的字符! 替换实例:last | tr ‘[a-z]’ ‘[A-Z]‘ 删除实例:cat /etc/passwd | tr -d ‘:’ |
| col | col [-xb] -x :将 tab 键转换成对等的空格键 实例:cat /etc/man_db.conf | col -x | cat -A | more |
| join | 将两文件中有相同数据的那一行才加一起。 join [-ti12] file1 file2 -t :join 默认以空格符分隔数据,并且比对『第一个字段』的数据, 如果两个文件相同,则将两笔数据联成一行,且第一个字段放在第一个! -i :忽略大小写的差异; -1 :这个是数字的 1 ,代表『第一个文件要用那个字段来分析』的意思; -2 :代表『第二个文件要用那个字段来分析』的意思。 实例一:join -t ‘:’ /etc/passwd /etc/shadow |head -n 3 实例二:join -t ‘:’ -1 4 /etc/passwd -2 3 /etc/group | head -n 3 |
| paste | 将两行贴在一起,且中间以 [tab] 键隔开 paste [-d] file1 file2 -d :后面可以接分隔字符。预设是以 [tab] 来分隔的! – :如果 file 部分写成 – ,表示来自 standard input 实例:cat /etc/group|paste /etc/passwd /etc/shadow -|head -n 3 |
| expand | 将tab键转为空格 expand [-t] file -t :接数字。一般来说,一个 tab 按键代替8 个空格键。 接数字意思是tab键代表几个空格 实例:grep ‘^MANPATH’ /etc/man_db.conf | head -n 3 | expand -t 6 – | cat -A |
| split | split [-bl] file PREFIX -b :接欲分区成的文件大小,可加b, k, m 等单位; -l :以行数来进行分区。 PREFIX :代表前导符,文件前缀。 实例:cd /tmp; split -b 300k /etc/services services |
| xargs | xargs [-0epn] command -0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空格键等等字符时,这个 -0 参数 可以将他还原成一般字符。这个参数可以用于特殊状态。 -e :这个是 EOF (end of file) 。后面接一个字符串,当 xargs 分析到这个字符串时, 就会停止继续工作! -p :在执行每个指令的 argument 时,都会询问使用者; -n :后面接次数,每次 command 指令执行时,要使用几个参数; 当 xargs 后面没有接任何的指令时,默认是以 echo 来进行输出。 实例一:cut -d ‘:’ -f 1 /etc/passwd | head -n 3 | xargs -p -n 1 id 实例二:cut -d ‘:’ -f 1 /etc/passwd | xargs -e’sync’ -n 1 id |
正则表达式
首先就有个要记下内容的表格:
特殊符号
| 特殊符号 | 代表意义 |
|---|---|
| [:alnum:] | 代表英文大小写字符以及数字,亦即【0-9】、【a-z】、【A-Z】 |
| [:alpha:] | 代表任何英文大小写字符,即【a-z】、【A-Z】 |
| [:blank:] | 代表空格键与【tab】键 |
| [:cntrl:] | 代表键盘上的控制键,即包括CR、LF、Tab、Del等等 |
| [:digit:] | 代表数字,即【0-9】 |
| [:graph:] | 代表除了空格键与【tab】键以外的其他所有按键 |
| [:lower:] | 表示所有小写字母,即【a-z】 |
| [:print:] | 代表所有可打印字符 |
| [:punct:] | 代表标点符号,即:”?’;!:#$等等 |
| [:upper:] | 代表大写字母,即【A-Z】 |
| [:space:] | 代表任何会产生空白的字符,包括空格键、Tab、CR等 |
| [:xdigit:] | 代表十六进制数字类型,即包括【0-9】、【a-f】、【A-F】 |
基础正则表达式符号及意义
| RE字符 | 意义与范例 |
|---|---|
| ^word | 意义:待搜寻的字串(word)在行首。 范例:搜寻行首为“#”开始的那一行,并列出行号。 grep -n ‘^#’ regular_express.txt |
| word$ | 意义:待搜寻的字串在行尾。 范例:将行尾为!的那一行打印出来,并列出行号。 grep -n ‘!$’ regular_express.txt |
| . | 意义:代表一个任意字符,而且是一定有这个字符。 范例:搜寻字串可以是(eve)(eae)(eee)(e e),但不能仅有(ee)!即e和e之间一定有且仅有一个字符,哪怕是空格字符。 grep -n ‘e.e’ regular_express.txt |
| \ | 意义:跳脱字符,将特殊符号的特殊意义去除。 范例:搜寻含有单’的那一行。 grep -n \’ regular_express.txt |
| * | 意义:重复零个到无穷多个前一个RE字符。 范例:找出含有(es)(ess)(esss)等的行。 grep -n ‘ess*’ regular_express.txt 注意:如果是任意字符,则需用“.\”来表达。例如:grep -n ‘g.\g’ regular_express.txt和grep -n ‘g*g’ regular_express.txt,前者表示搜寻首尾是g中间一定有字符的字串如gag,后者表示搜寻g、gg、ggg等 |
| [list] | 意义:字符集合的RE字符,里面列出想搜取的字符,注意,是只取所列字符中的一个。 范例:搜寻含有(gl)或者(gd)的行。 grep -n ‘g[ld]’ regular_express.txt |
| [n1-n2] | 意义:字符集合的RE字符,里面李处想搜取的字符的范围。 范例:搜寻所有大写字符。 grep -n ‘[A-Z]’ regular_express.txt |
| [^list] | 意义:字符集合的RE字符,里面列出不要的字符串或者范围。 范例:不要列出(oot)的字串,但可以是(ooa)(oog)(oob)之类。 grep -n ‘oo[^t]’ regular_express.txt |
| {n,m} | 意义:连续n到m个的“前一个RE字符”。 意义:如果是{n}则是连续n个的前一个RE字符。 意义:如果是{n,}则是连续n个以上的前一个RE字符。 范例:搜寻在g和g之间有2到3个‘o’字符的字符串。 grep -n ‘go\{2,3\}g’ regular_express.txt |
列出以‘a’开头的文件:ls \|grep -n '^a.\*'
列出/etc下文件类型为链接文件的文件名ls -l /etc \|grep -n '^l'
sed用法
sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。一般用法中,sed会将来自STDIN的所有数据(包括sed处理过的)都列在屏幕中,只有加-n参数,才会仅列被sed处理的那些行。
-e :直接在指令模式上进行sed的编辑动作。
-f :直接将sed的动作写在一个文件内,-f filename则可以执行filename内的sed动作。
-r :sed动作支持的是扩展正则表达式的语法。
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]] function
n1、n2不一定需要,但是它代表要进行处理的行数。
function下的具体指令:
a :新增,a后面可接字符串,而这些字符串会在目前行的下一行出现(新的一行)
c :取代,c后面可接字符串,而这些字符串可取代n1,n2之间的行。
d :删除,d后面不接东西。
i :插入,i后面可接字符串,而这些字符串在目前行的上一行出现(新的一行)
p :打印,亦即将某个选择的数据印出。通常和sed -n 一起使用。
s :取代,可以直接进行取代的工作。s通常搭配正则表达是使用,例如:1,20s/old/new/g
/sbin/ifconfig eth0 | grep ‘inet ‘ | sed ‘s/^.*inet //g’ \ | sed ‘s/ *netmask.*$//g’
这例子是取出eth0接口的IP地址值
cat /etc/man_db.conf | grep ‘MAN’| sed ‘s/#.*$//g’ | sed ‘/^$/d’
这个例子是查看man_db.conf文件内容并去除掉#开头的注释内容和空白行。
sed -i ‘s/\.$/\!/g’ regular_express.txt
将 regular_express.txt 内每一行结尾若为 . 则换成!
sed -i ‘$a # This is a test’ regular_express.txt
直接在 regular_express.txt 最后一行加入『# This is a test』
扩展正则表达式
与扩展正则表达式有关的命令是egrep,或者说是grep -E。
其涉及的RE字符见下表:
| RE字符 | 意义与范例 |
|---|---|
| + | 意义:重复一个或一个以上前一个RE字符 范例:搜寻(god)(good)(goood)等字符串。 egrep -n ‘go+d’ regular_express.txt |
| ? | 意义:重复0个或一个RE字符。 范例:搜寻(gd)和(god)这2个字符串。 egrep -n ‘go?d’ regular_express.txt |
| | | 意义:用或(or)的方式找寻字符串。 范例:搜寻gd或good或dog这三个字符串。 egrep -n ‘d\good\dog’regular_express.txt |
| () | 意义:寻找“群组”字符串。 范例:找寻(good)或(glad)两个字符串。 egrep -n ‘g(oo|la)d’ regular_express.txt |
| ()+ | 意义:多个重复群组的判别。 范例:搜寻类似“AxyzxyzxyzxyzC”这样的字符串。 egrep -n ‘A(xyz)+C’ regular_express.txt |
文件格式化与相关处理
printf命令
print命令用法:
printf ‘打印格式’ 实际内容
注意:这里的“打印格式”是被单引号(”)包括起来的
关于“打印格式”,这里列出一些特殊样式(其实下列就是一些控制输出格式内容的转义符),有助于下面范例内容的理解。
\a 警告声音输出
\b 退格键(backspace)
\f 清除屏幕(from feed)
\r 即Enter按键
\t 水平的‘tab’键
\v 垂直的‘tab’键
\xNN NN为两位数字,可以转换数字成为字符。
\\ 代表反斜杠本身,用两个反斜杠转义出一个字面意义上的反斜杠。
\% 代表
其中用的最多的,应该就是“\t”、“\v”、“\r”了。这些特殊样式,配合下列常见的格式替换符(格式替换方式),是比较常见的printf列印输出方式。
%ns 那个n是数字,s代表字符串,连起来就是多少个字符串的意思,比如“%20s”。
%ni 那个n是数字,i代表整数,连起来代表多少整数,比如“%8i”。
%N.nf 大N和小n都代表数字,f代表浮点数floating,假设浮点数整体是8位,小数点后面是3位,那么表示为“%8.3f”,即整数部分5位,小数点后是3位,合起来8位。
参看下面的例子:
printf ‘%10s %5i %5i %5i %8.2f \n’ $(cat printf.txt | grep -v Name)
printf ‘\x45\n’ —— 这个例子是“列出16进制数值45是啥字符的意思”
其实printf命令源自于C语言里的printf()函数,两者的格式替换方式(或者说输出控制方式)是一样的。
这里再列出一些“输出控制符”(其实囊括了前面的那些“%ns”、“%ni”、“%N.nf”了)
| 控制符 | 意义 |
|---|---|
| %d | 按十进制整型数据的实际长度输出。 |
| %ld | 输出长整型数据。 |
| %nd | n 为指定的输出字段的宽度。如果数据的位数小于 n,则左端补以空格,若大于 n,则按实际位数输出。 |
| %u | 输出无符号整型(unsigned)。输出无符号整型时也可以用 %d,这时是将无符号转换成有符号数,然后输出。 |
| %c | 用来输出一个字符。 |
| %f | 用来输出实数,包括单精度和双精度,以小数形式输出。不指定字段宽度,由系统自动指定,整数部分全部输出,小数部分输出 6 位,超过 6 位的四舍五入。 |
| %.nf | 输出实数时小数点后保留 n位,注意 n 前面有个点。 |
| %o | 以八进制整数形式输出,这个就用得很少。 |
| %s | 用来输出字符串。 |
| %x(或 %X 或 %#x 或 %#X) | 以十六进制形式输出整数,这个很重要。 |
网上有篇写printf命令的文章,很是浅显易懂,这里放上链接。
awk命令
awk不同于sed,后者是用来处理单行数据的,前者是更偏向于格式化处理文本文件,其基础使用方式是这样的:
awk ‘条件类型1{动作1} 条件类型2{动作2} …’ filename
常见的例子:
last -n 5 | awk ‘{print $1 “\t” $3}’
awk有几个内建变量
| 变量名称 | 意义 |
|---|---|
| NF | 每一行 ($0) 拥有的字段总数 |
| NR | 目前 awk 所处理的是『第几行』数据 |
| FS | 目前的分隔字符,默认是空格键 |
以上面 last -n 5 的例子:
列出每一行的账号就是 ($1) ;
列出目前处理的行数 (就是 awk 内的 NR 变量 )
该行有多少字段 (就是 awk 内的 NF 变量 )
last -n 5| awk ‘{print $1 “\t lines: ” NR “\t columns: ” NF}’
单用户模式下关机或者重启
echo b > /proc/sysrq-trigger ##这是reboot重启
echo o > /proc/sysrq-trigger ##这是关机